-
Spring Batch - Chunk 지향 처리🌱 spring/🚛 spring batch 2022. 12. 16. 01:35
📌 Chunk 지향 처리
Chunk 지향 처리는 Spring Batch의 큰 장점 중 하나이다.
❔ Chunk
Spring Batch에서 Chunk 란 데이터 덩어리로 작업할 때 각 커밋사이에 처리되는 row의 수이다.
즉, Chunk 지향 처리란
- 한 번에 하나씩 데이터를 읽어 Chunk 라는 덩어리를 만든 뒤
- Chunk 단위로 트랜잭션을 다루는 것이다.
Chunk 단위로 트랜잭션을 수행하기 때문에
- 실패할 경우 해당 Chunk 만큼만 롤백
- 이전에 커밋된 트랜잭션 범위까지는 반영이 된다.
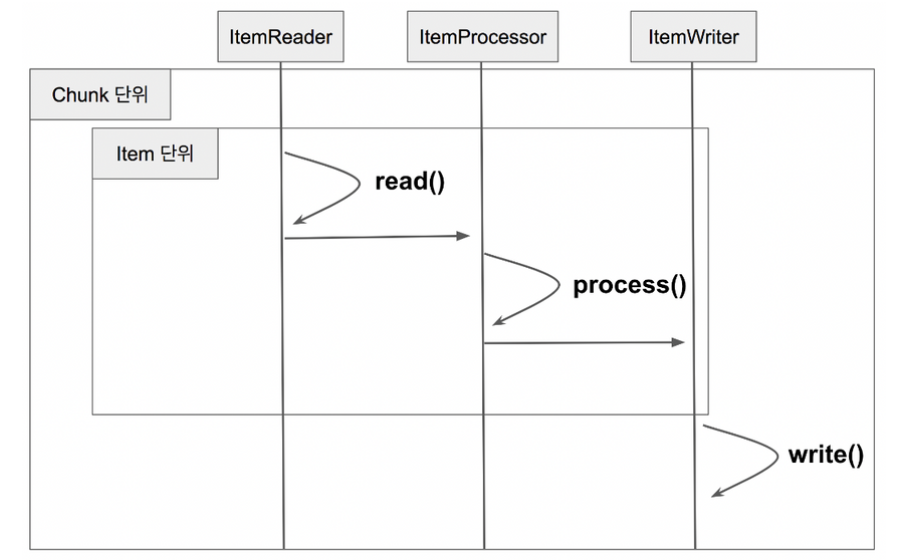
- Reader에서 데이터를 하나 읽어온다
- 읽어온 데이터를 Processor에서 가공한다.
- 가공된 데이터들을 별도의 공간에 모은뒤, Chunk 단위만큼 쌓이게 되면 Writer에 전달하고 Writer는 일괄 저장한다.
Reader, Processor 에서는 1건씩 다뤄지고, Writer에선 Chunk 단위로 처리가 된다.
간단한 자바코드로 표현
for(int i = 0; i< totalSize; i += chunkSize) { // chunkSize 단위로 묶어서 처리 List items = new Arraylist(); for(int j = 0; j < chunkSize; j++){ Object item = itemReader.read() Object processedItem = itemProcessor.process(item); items.add(processedItem); } itemWriter.write(items); }ChunkOrientedTasklet
Spring Batch에서 Chunk 지향 처리의 전체 로직을 다루는 것은 ChunkOrientedTasklet 클래스이다.
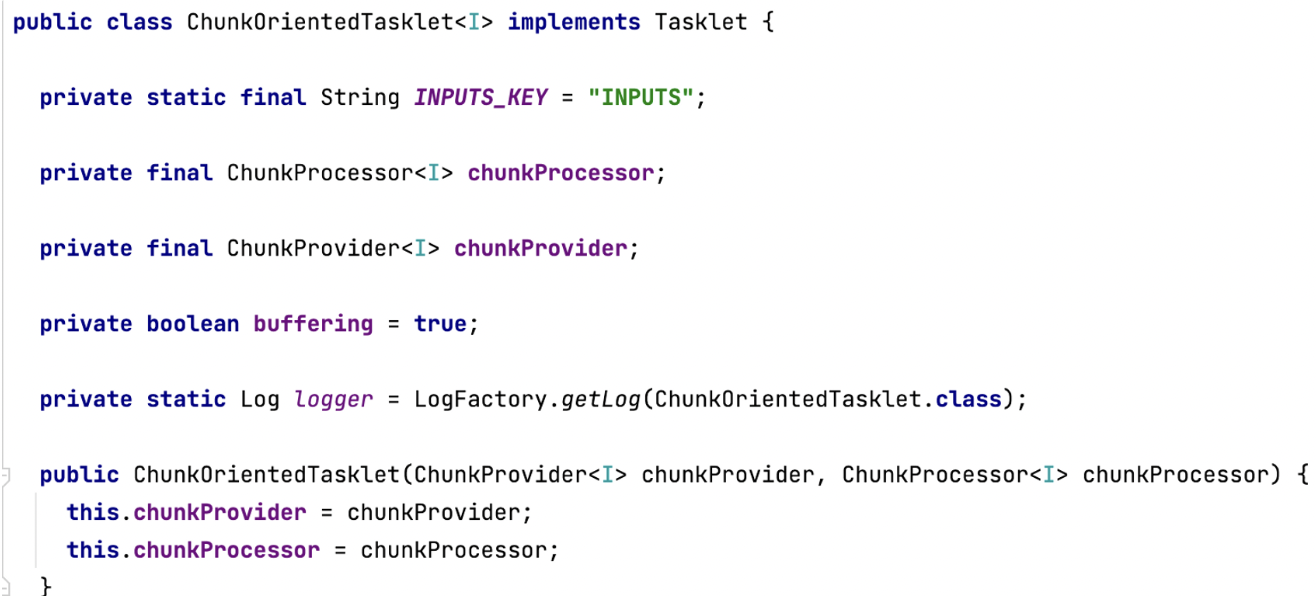
ChunkOrientedTasklet의 execute()
@Nullable @Override public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception { @SuppressWarnings("unchecked") Chunk<I> inputs = (Chunk<I>) chunkContext.getAttribute(INPUTS_KEY); if (inputs == null) { inputs = chunkProvider.provide(contribution); // Reader에서 데이터 가져옴 if (buffering) { chunkContext.setAttribute(INPUTS_KEY, inputs); } } chunkProcessor.process(contribution, inputs); // Processor & Writer 처리 chunkProvider.postProcess(contribution, inputs); // Allow a message coming back from the processor to say that we // are not done yet if (inputs.isBusy()) { logger.debug("Inputs still busy"); return RepeatStatus.CONTINUABLE; } chunkContext.removeAttribute(INPUTS_KEY); chunkContext.setComplete(); if (logger.isDebugEnabled()) { logger.debug("Inputs not busy, ended: " + inputs.isEnd()); } return RepeatStatus.continueIf(!inputs.isEnd()); }- chunkProvider.provide() : Reader에서 Chunk size 만큼 데이터를 가져온다.
- chunkProcessor.process() : Reader에서 받은 데이터를 가공(process)하고 저장(write)한다.
chunkProvider.provide()
- Chunk가 ChunkSize 만큼 쌓일 때 까지 read()를 호출한다.
- read()는 ItemReader.read 를 호출한다.
- ItemReader.read 에서 1건씩 데이터를 조회하여 Chunk size 만큼 데이터를 쌓는다.
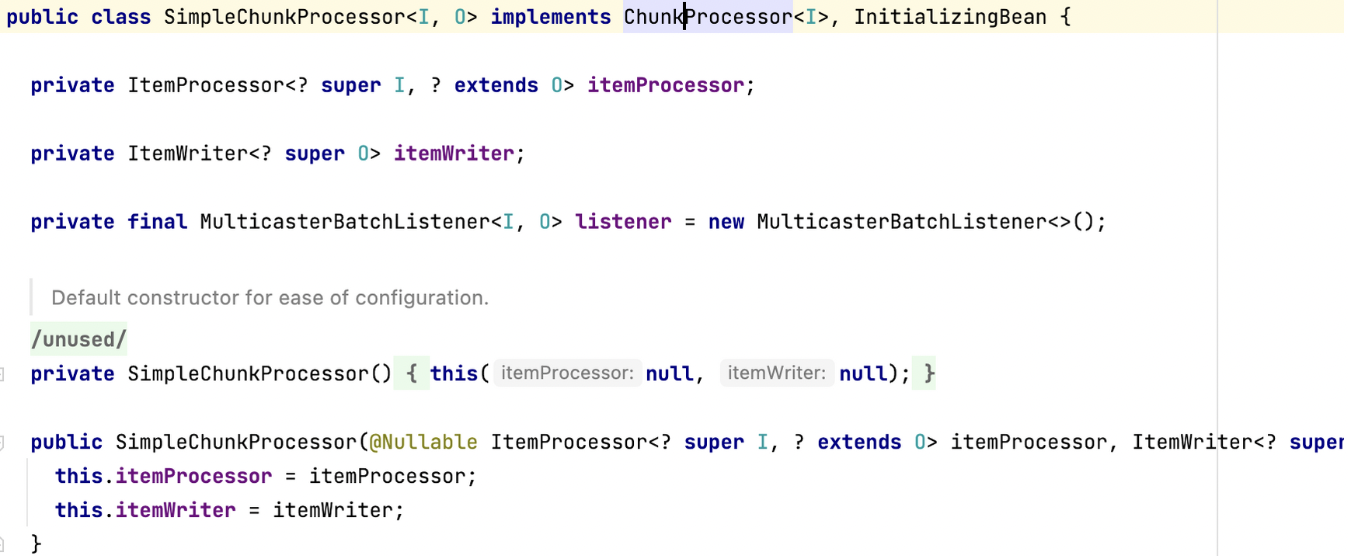
SimpleChunkProcessor
- ChunkSize 만큼 쌓은 데이터를 어떻게 가공하고 저장하는가❓
Processor와 Writer 로직을 담고 있는 것은 ChunkProcessor 가 담당하고 있다.

- 인터페이스
SimpleChunkProcessor가 기본적으로 사용하는 실제 구현체이다.
SimpleChunkProcessor의 process() - 처리를 담당하는 핵심 로직
@Override public final void process(StepContribution contribution, Chunk<I> inputs) throws Exception { // Allow temporary state to be stored in the user data field initializeUserData(inputs); // If there is no input we don't have to do anything more if (isComplete(inputs)) { return; } // Make the transformation, calling remove() on the inputs iterator if // any items are filtered. Might throw exception and cause rollback. Chunk<O> outputs = transform(contribution, inputs); // Adjust the filter count based on available data contribution.incrementFilterCount(getFilterCount(inputs, outputs)); // Adjust the outputs if necessary for housekeeping purposes, and then // write them out... write(contribution, inputs, getAdjustedOutputs(inputs, outputs)); }- Chunk<I> inputs 를 파라미터로 받는다.
- chunkProvider.provide()에서 받은 ChunkSize만큼 쌓인 item
- transform()에서는 전달받은 inputs을 doProcess()로 전달하고 변환값을 받는다.
- transform()에서 가공된 대량의 데이터는 writer()를 통해 일괄 저장된다.
- writer()는 저장이 될수도 있고 외부 API로 전송할 수도 있다.
- 이는 개발자가 ItemWriter를 어떻게 구현했는지에 따라 다르다.
transform()
protected Chunk<O> transform(StepContribution contribution, Chunk<I> inputs) throws Exception { Chunk<O> outputs = new Chunk<>(); for (Chunk<I>.ChunkIterator iterator = inputs.iterator(); iterator.hasNext();) { final I item = iterator.next(); O output; Timer.Sample sample = BatchMetrics.createTimerSample(); String status = BatchMetrics.STATUS_SUCCESS; try { output = doProcess(item); } catch (Exception e) { /* * For a simple chunk processor (no fault tolerance) we are done * here, so prevent any more processing of these inputs. */ inputs.clear(); status = BatchMetrics.STATUS_FAILURE; throw e; } finally { stopTimer(sample, contribution.getStepExecution(), "item.process", status, "Item processing"); } if (output != null) { outputs.add(output); } else { iterator.remove(); } } return outputs; }- 반복문을 통해 doProcess()를 호출한다.
- doProcess()는 ItemProcessor의 process()를 사용한다.
protected final O doProcess(I item) throws Exception { if (itemProcessor == null) { @SuppressWarnings("unchecked") O result = (O) item; return result; } try { listener.beforeProcess(item); O result = itemProcessor.process(item); listener.afterProcess(item, result); return result; } catch (Exception e) { listener.onProcessError(item, e); throw e; } }- doProcess()를 처리하는데 만약 ItemProcessor 가 없다면 item을 그대로 반환한다.
- 있다면 process()로 가공하여 반환한다.
가공된 데이터들은 SimpleChunkProcessor의 doWriter()를 호출하여 일괄 처리가 된다.
⚠️ Page Size vs Chunk Size
Chunk Size : 한번에 처리될 트랜잭션 단위
Page Size : 한번에 조회할 Item의 양
Page Size
- Page 단위로 끊어서 조회하는 것
- 페이징 쿼리에서 Page의 Size를 지정하기 위함
Page Size가 10, Chunk Size가 50 인 경우 ItemReader에서 Page 조회가 5번 일어나면❓
- 1 번의 트랜잭션이 발생하여 Chunk가 처리가 된다.
- 한 번의 트랜잭션 처리를 위해 5번의 쿼리 조회가 발생 → 성능상 이슈가 발생할 수 있다.
Page size 와 Chunk Size의 값을 일치시키는 것이 보편적으로 좋은 방법이다.
참고자료
https://jojoldu.tistory.com/331?category=902551
'🌱 spring > 🚛 spring batch' 카테고리의 다른 글
Spring Batch - ItemWriter (0) 2022.12.16 SpringBatch - ItemReader (0) 2022.12.16 Spring Batch - Scope (0) 2022.12.16 Spring Batch - Job Flow (0) 2022.12.16 메타데이터 테이블 (0) 2022.12.16