-
2장 - 카프카 빠르게 시작해보기📕 book/아파치 카프카 2023. 1. 12. 18:05
📍 AWS EC2 인스턴스 발급 및 보안 설정
AWS에서 카프카를 구축하는 2가지 방법
- MSK(Managed Service Kafka) 사용
- EC2에서 설치 및 실행
MSK
- AWS에서 공식적으로 지원하는 완전 관리형 카프카 서비스
- 간단한 콘솔 세팅으로 AWS에서 카프카 설치 및 실행을 자동화해준다.
실습을 위한 카프카를 위해서 실행되는 프로세스 : 주키퍼, 카프카 브로커
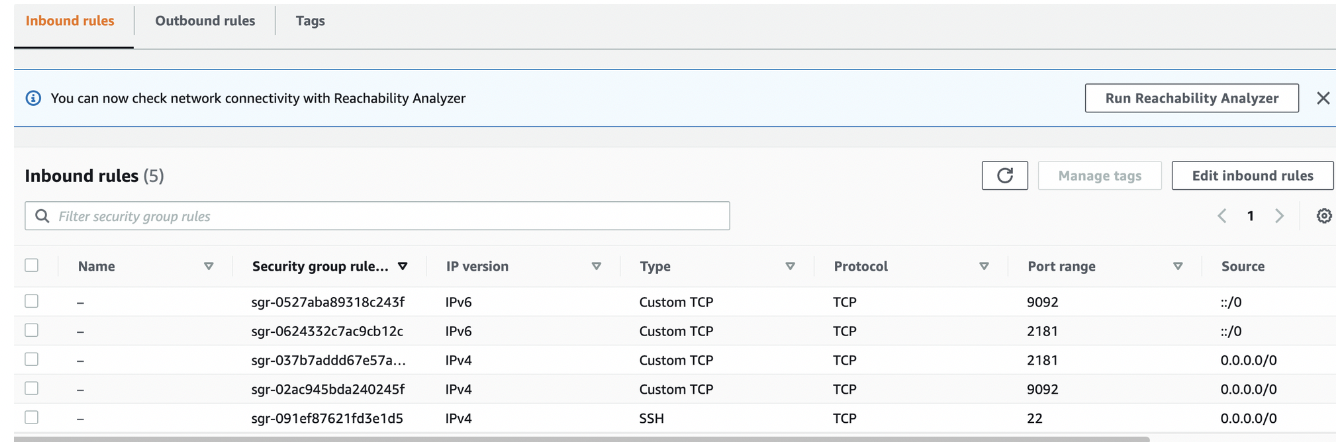
카프카 브로커의 기본 포트는 9092, 주키퍼의 기본 포트는 2181이다.
EC2에 설치하는 브로커에 접속하기 위해서는 AWS EC2의 보안그룹의 Inbound 설정에 9092와 2181 포트를 열어야 한다.
- 실습용이므로 모든 IP로부터 접속 가능하도록 설정
주키퍼
💡 주키퍼는 분산 코디네이션 서비스를 제공하는 오픈소스이다.
분산 코디네이션 서비스
- 분산 시스템 내부에 상태 정보를 저장하고 데이터를 key/value 저장소로 저장 및 제공하는 서비스
❗ 카프카에서는 주키퍼를 운영에 필요한 각종 설정과 상태들을 저장하는데 사용한다.
↩️ 인스턴스 접속
ssh 명령어로 접속하기
ssh
- 네트워크 상의 다른 컴퓨터에 접속할 때 사용하는 명령어
EC2 인스턴스에 접속하기 위해서는 -i 옵션을 사용해 key pair 파일(~.pem)을 프라이빗 키로 추가해야 한다.
- -i : 비밀 키를 읽어올 파일의 경로를 추가하는 옵션
key pair 파일을 명령어로 읽어오 기위해서는 유저 권한을 변경해야 한다.
- 인스턴스 접속를 위해서는 key pair파일이 read 권한만 가지고 있어야 한다.
chmod 400 test-kafka-server-key.pem // 유저 권한 변경 ll test-kafka-server-key.pem접속
ssh -i test-kafka-server-key.pem ec2-user@{인스턴스IP}📌 인스턴스에 자바 설치
카프카 브로커를 실행하기 위해서는 JDK가 필요하다.
- 카브카 브로커는 스칼라와 자바로 작성되에 JVM 환경 위에서 실행되기 때문
설치
sudo yum install -y java-1.8.0-openjdk-devel.x86_64 java -version📌 주키퍼 • 카프카 브로커 실행
카프카 바이너리 패키지
카프카 브로커를 실행하기 위해서 카프카 바이너리 패키지를 다운로드한다.
- 카프카 바이너리 패키지에는 자바 소스코드를 컴파일하여 실행하기 위해 준비해 놓은 바이너리 파일들이 들어있다.
wget 명령어와 바이너리 패키지의 URL을 통해 카프카 패키지를 EC2 인스턴스에 다운로드 받을 수 있다.
wget <https://archive.apache.org/dist/kafka/2.5.0/kafka_2.12-2.5.0.tgz>카프카 브로커 힙 메모리 설정
카프카 브로커를 실행하기 위해서는 힙 메모리 설정이 필요
❓why
- 카프카 브로커는 레코드의 내용은 페이지 캐시로 시스템 메모리를 사용
- 나머지 객체들은 힙 메모리에 저장하여 사용
- 이런 특징으로 카프카 브로커 운영시 힙 메모리를 5GB 이상으로 설정하지 않는 것이 일반적
환경 변수 설정
export KAFKA_HEAP_OPTS="-Xmx400m -Xms400m" echo $KAFKA_HEAP_OPTS // 정상적으로 설정되었는지 확인- ❗ 터미널에서 입력한 환경변수는 터미널 세션이 종료되고 나면 초기화된다 ⇒ 재사용 불가
- 해결 → 환경변수 선언문을 ~/.bashrc 파일에 넣는다.
- ~/.bashrc 파일은 bash 쉘이 실행될 때마다 반복적으로 구동되어 적용되는 파일이다.
vi ~/.bashrc // 파일에 export KAFKA_HEAP_OPTS="-Xmx400m -Xms400m" 추가 source ~/.bashrc // source명령어 : 스크립트 파일을 수정한 후 수정된 값을 바로 적용하기 위해 사용해당 환경변수는 kafka-server-start.sh 스크립트 내부에서 사용한다.
... if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G" fi EXTRA_ARGS=${EXTRA_ARGS-'-name kafkaServer -loggc'} COMMAND=$1 case $COMMAND in -daemon) EXTRA_ARGS="-daemon "$EXTRA_ARGS shift ;; *) ;; esac exec $base_dir/kafka-run-class.sh $EXTRA_ARGS kafka.Kafka "$@"- KAFKA_HEAP_OPTS 이 환경변수로 지정되어 있지 않으면 기본 힙 메모리는 Xmx 1GB, Xms 1GB로 설정
- -daemon 옵션
- 카프카 브로커가 실행될 때 백그라운드로 실행될지 포어그라운드로 실행될지 설정
- 옵션을 붙이면 백그라운드 ⇒ 터미널의 세션이 끊기더라도 카프카 브로커는 계속해서 동작
카프카 브로커 실행 옵션 지정
💡 config/server.properties 파일에 카프카 브로커가 클러스터 운영에 필요한 옵션들을 지정할 수 있다.
- 카프카 브로커 번호
- 통신을 위해 열어둘 인터페이스 IP, port, 프로토콜 설정
- 카프카 클라이언트 또는 카프카 커맨드 라인 툴에서 접속 시 사용하는 IP, port 정보
- 등등
advertised.listener 옵션
- 카프카 클라이언트 또는 커맨드 라인 툴을 브로커와 연결할 때 사용
주키퍼 실행
카프카 바이너리가 포함된 폴더에는 브로커와 같이 실행할 주키퍼가 준비되어 있다.
주키퍼는
- 카프카의 클러스터 설정 리더 정보
- 컨트롤러 정보
를 담고 있어 카프카를 실행하는 데 필요한 필수 애플리케이션이다.
⚠️ 주키퍼를 상용환경에서 안전하게 운영하기 위해서는 3대 이상의 서버로 구성하여 사용한다.
- 실습에서는 동일 서버에 카프카와 주키퍼를 1대만 실행시켜 사용
- 1대만 실행하는 주키퍼 - “Quick-and-dirty single-node” 라 한다.
- 주키퍼 1대만 실행하여 사용하는 것은 비정상적인 운영이다.
- 테스트 목적으로만 사용해야 한다.
실행
bin/zookeeper-server-start.sh -daemon config/zookeeper.properties // 백그라운드 실행 jps -vm // 주키퍼가 정상적으로 실행되었는지 확인jps
- JVM 프로세스 상태를 보는 도구
- JVM 위에서 동작하는 주키퍼의 프로세스를 확인할 수 있다.
카프카 브로커 실행 및 로그 확인
브로커 실행
bin/kafka-server-start.sh -daemon config/server.properties // 백그라운드 실행 jps -m // 주키퍼, 브로커 프로세스 동작여부 확인 tail -f logs/server.log // 로그를 확인해 카프카 브로커가 정상 동작하는지 확인⭐ 카프카 브로커 로그 확인
- 카프카 클라이언트를 개발할 때뿐만 아니라 카프카 클러스터를 운영할 때 이슈가 발생할 경우 모두 카프카 브로커에 로그가 남는다.
- 따라서 로그를 확인하는 것은 매우 중요하다.
📌 로컬 컴퓨터에서 카프카와 통신 확인
로컬 컴퓨터에서 원격으로 카프카 브로커로 명령을 내려 정상적으로 통신하는지 확인
- 카프카 브로커 정보 요청
카프카 바이너리 패키지는 카프카 브로커에 대한 정보를 가져올 수 있는 kafka-broker-api-versions.sh 명령어 제공
- 로컬에서 카프카 바이너리 패키지를 다운
통신
bin/kafka-broker-api-versions.sh --bootstrap-server {인스턴스 IP}:9092- —bootstrap-server 에 인스턴스 IP와 포트를 넣는다.
- 원격으로 카프카의 버전과 broker.id, rack 정보, 각종 카프카 브로커 옵션을 확인할 수 있다.

🔨 카프카 커맨드 라인 툴
💡 카프카에서 제공하는 카프카 커맨드 라인툴들은 카프카 운영시 가장 많이 접하는 도구이다.
- 카프카 브로커 운영에 필요한 다양한 명령을 내릴 수 있다.
kafka-topics.sh
이 커맨드 라인 툴을 통해 토픽과 관련된 명령을 실행할 수 있다.
📖 토픽
- 카프카에서 데이터를 구분하는 가장 기본적인 개념
- 카프카 클러스트에 토픽은 여러개 존재할 수 있다.
📖 파티션- 토픽에는 파티션이 존재
- 최소 1개
- 카프카에서 토픽을 구성하는 데 아주 중요한 요소
토픽 생성
kafka-topics.sh 를 통해 토픽 관련 명령을 실행할 수 있다.
// 로컬 bin/kafka-topics.sh \\ --create \\ // --create 옵션: 토픽을 생성하는 명령어 --bootstrap-server {인스턴스 IP}:9092 \\ // 토픽을 생성할 카프카 클러스터를 구성하는 브로커들의 IP, Port를 적는다. --topic hello.kafka \\ // --topic : 토픽 이름 작성- 이렇게 만들어진 토픽은 브로커에 설정된 기본값으로 생성 (다양한 옵션)
옵션 지정하여 생성
// 로컬 bin/kafka-topics.sh \\ --create \\ --bootstrap-server {인스턴스 IP}:9092 \\ --partitions 3 \\ // 파티션 개수 지정 --replication-factor 1 \\ // 토픽의 파티션을 복제할 복제 개수 --config retention.ms=172800000 \\ // --config: kafka-topics.sh 명령에 포함되지 않은 추가적인 설정을 할 수 있다. // retention.ms : 토픽의 데이터를 유지하는 기간 --topic hello.kafka.2 \\토픽 리스트 조회
bin/kafka-topics.sh --bootstrap-server {인스턴스IP}:9092 --list
토픽 상세 조회
bin/kafka-topics.sh --bootstrap-server {인스턴스IP}:9092 --describe --topic hello.kafka.2- 이미 생성된 토픽의 상태를 —describe 옵션을 사용하여 확인할 수 있다.
토픽 옵션 수정
토픽에 설정된 옵션을 변경하기 위해서는 kafka-topics.sh 또는 kafka-configs.sh 두개를 사용해야 한다.
kafka-topics.sh
- 파티션 개수 변경
kafka-configs.sh
- 토픽 삭제 정책인 리텐션 기간 변경
bin/kafka-topics.sh --bootstrap-server {인스턴스IP}:9092 \\ --topic hello.kafka \\ --alter \\ --partitions 4 bin/kafka-topics.sh --bootstrap-server {인스턴스IP}:9092 \\ --topic hello.kafka \\ --describe bin/kafka-configs.sh --bootstrap-server {인스턴스IP}:9092 \\ --entity-type topics \\ --entity-name hello.kafka \\ --alter --add-config retention.ms=86400000 bin/kafka-configs.sh --bootstrap-server {인스턴스IP}:9092 \\ --entity-type topics \\ --entity-name hello.kafka \\ --describe- —alter 옵션과 —partitions 옵션을 함께 사용 ⇒ 파티션 개수 변경
- ❗ 토픽의 파티션을 늘릴수는 있지만 줄일 순 없다.
- 따라서 판단을 잘해야 함!!
- retention.ms 을 수정하기 위해 kafka-configs.sh와 —alter, —add-config 옵션 사용
- —add-config 옵션 : 이미 존재하는 설정값은 변경하고 존재하지 않는 설정값은 신규로 추가
kafka-console-producer.sh
💡 생성한 토픽에 데이터를 넣는 명령어
📖 레코드(record)
- 토픽에 넣는 데이터
- 메시지 키(key)와 데이터 값(value)로 이루어져 있다.
메시지 키 없이 메시지 값만 보내는 경우
bin/kafka-console-producer.sh --bootstrap-server {인스턴스IP}:9092 \\ --topic hello.kafka > hello > kafka > 0 > 1 > 2 > 3 > 4 > 5⚡ kafka-console-producer.sh 로 전송되는 레코드 값은 UTF-8을 기반으로 Byte로 변환된다.
- ByteArraySerializer로만 직렬화가 된다.
즉, String이 아닌 타입으로는 직렬화 하여 전송할 수 없다.
그러므로 텍스트 목적으로 문자열만 전송할 수 있다.
다른 타입으로 직렬화하여 데이터를 브로커로 전송하고 싶다면 카프카 프로듀서 애플리케이션을 직접 개발해야 한다.
메시지 키를 가지는 레코드 전송
bin/kafka-console-producer.sh --bootstrap-server {인스턴스IP}:9092 \\ --topic hello.kafka \\ --property "parse.key=true" \\ --property "key.separator=:" >key1:no1 >key2:no2 >key3:no3- parse.key 를 true로 두면 레코드 전송 시 메시지키를 추가할 수 있다.
- key.separator : 메시지 키와 메시지 값을 구분하는 구분자 선언
- 기본 설정 - Tab(\t)
메시지 키와 메시지 값을 함께 전송한 레코드는 토픽의 파티션에 저장된다.
메시키 키가 null 인 경우
- 프로듀서가 파티션으로 전송할 때 레코드 배치 단위로 라운드 로빈으로 전송
메시지 키가 존재하는 경우
- 키의 해시값을 작성해 존재하는 파티션 중 한개에 할당
- 메시지 키가 동일한 경우 동일한 파티션으로 전송
- 커스턴 파티셔너를 사용할 경우 메시지 키에 따른 파티션 할당이 다르게 동작할 수 있다.
kafka-console-consumer.sh
💡 토픽으로 전송한 데이터는 kafka-console-consumer.sh 명령어로 확인할 수 있다.
필수 옵션
- —bootstrap-server
- 카프카 클러스터 정보
- —topic
- 토픽 이름
추가 옵션
—from-beginning
- 토픽에 저장된 가장 처음 데이터부터 출력
bin/kafka-console-consumer.sh --bootstrap-server {인스턴스IP}:9092 \\ --topic hello.kafka \\ --from-beginning- 전송했던 데이터의 순서가 출력되는 순서와 다르다.
- 파티션 개념에 의해 생기는 현상
- 토픽의 데이터를 가져갈 때 모든 파티션으로부터 동일한 중요도로 데이터를 가져간다.
- 순서 보장하는 가장 좋은 방법 - 파티션 1개로 구성된 토픽을 만드는 것.
메시지 키와 메시지 값을 확인하고 싶은 경우
bin/kafka-console-consumer.sh --bootstrap-server {인스턴스IP}:9092 \\ --topic hello.kafka \\ --property print.key=true \\ // 메시지 키를 확인하기 위한 설정 --property key.separator="-" \\ // 메시지 키 값을 구분하기 위한 설정 --group hello-group \\ // --group 옵션을 통해 신규 컨슈머 그룹 생성 --from-beginning📖 컨슈머 그룹
- 1개 이상의 컨슈머로 이루어져 있다.
- 컨슈머 그룹을 통해 가져간 토픽의 메시지는 가져간 메시지에 대해 커밋을 한다.
📖 커밋- 컨슈머가 특정 레코드까지 처리를 완료했다고 레코드의 오프셋 번호를 카프카 브로커에 저장하는 것.
- 커밋정보는 __consumer_offsets 이름의 내부 토픽에 저장된다.
kafka-consumer-groups.sh
컨슈머 그룹은 따로 생성하는 명령을 날리지 않고 컨슈머를 동작할 때 컨슈머 그룹 이름을 지정하면 새로 생성된다.
컨슈머 그룹 리스트 확인
bin/kafka-consumer-groups.sh --bootstrap-server {인스턴스 IP}:9092 --list컨슈머 그룹 이름 토대로 컨슈머 그룹이 어떤 토픽의 데이터를 가져가는지 확인
bin/kafka-consumer-groups.sh --bootstrap-server {인스턴스 IP}:9092 \\ --group hello-group \\ --describe
- 조회한 컨슈머 그룹이 마지막으로 커밋한 토픽과 파티션
- 첫 번째 줄 - hello-group 이름의 컨슈머 그룹이 hello.kafka 토픽의 3번 파티션의 레코드가 마지막으로 커밋
- 컨슈머 그룹이 가져간 토픽의 파티션에 가장 최신 오프셋이 몇번인지
- 3번 파티션에 가장 최신 오프셋은 3으로 3개의 데이터가 들어갔음을 알 수 있다.
- 컨슈머 그룹의 컨슈머가 어느 오프셋까지 커밋했나
- 랙(Lag) 확인
- 컨슈머의 토픽 할당을 카프카 내부적으로 구분하기 위해 사용하는 id
- 컨슈머가 동작하는 host명 출력
- 카프카에 붙은 컨슈머의 호스트명 또는 IP를 알 수 있다.
- 컨슈머에 할당된 id
📖 오프셋
- 파티션의 각 레코드에 할당된 번호
- 데이터가 파티션에 들어올때마다 1씩 증가
📖 랙(Lag)- 컨슈머 그룹이 토픽의 파티션에 있는 데이터를 가져가는 데 얼마나 지연이 발생하는지 나타내는 지표
- 컨슈머 그룹이 커밋한 오프셋과 해당 파티션의 가장 최신 오프셋 간의 차이
kafka-verifiable-producer, consumer.sh
💡 kafka-verifiable 로 시작하는 2개의 스크립트를 사용하면 String 타입 메시지 값을 코드 없이 주고 받을 수 있다.
- 토픽에 데이터를 전송하여 간단한 네트워크 통신 테스트를 할 때 유용
전송
bin/kafka-verifiable-producer.sh --bootstrap-server {인스턴스 IP}:9092 \\ --max-messages 10 \\ --topic verify-test {"timestamp":1673512722372,"name":"startup_complete"} {"timestamp":1673512722615,"name":"producer_send_success","key":null,"value":"0","offset":0,"topic":"verify-test","partition":0} {"timestamp":1673512722617,"name":"producer_send_success","key":null,"value":"1","offset":1,"topic":"verify-test","partition":0} {"timestamp":1673512722617,"name":"producer_send_success","key":null,"value":"2","offset":2,"topic":"verify-test","partition":0} {"timestamp":1673512722617,"name":"producer_send_success","key":null,"value":"3","offset":3,"topic":"verify-test","partition":0} {"timestamp":1673512722617,"name":"producer_send_success","key":null,"value":"4","offset":4,"topic":"verify-test","partition":0} {"timestamp":1673512722617,"name":"producer_send_success","key":null,"value":"5","offset":5,"topic":"verify-test","partition":0} {"timestamp":1673512722617,"name":"producer_send_success","key":null,"value":"6","offset":6,"topic":"verify-test","partition":0} {"timestamp":1673512722617,"name":"producer_send_success","key":null,"value":"7","offset":7,"topic":"verify-test","partition":0} {"timestamp":1673512722617,"name":"producer_send_success","key":null,"value":"8","offset":8,"topic":"verify-test","partition":0} {"timestamp":1673512722617,"name":"producer_send_success","key":null,"value":"9","offset":9,"topic":"verify-test","partition":0} {"timestamp":1673512722620,"name":"shutdown_complete"} {"timestamp":1673512722621,"name":"tool_data","sent":10,"acked":10,"target_throughput":-1,"avg_throughput":40.16064257028113}- 최초 실행 시점 - startup_complete 와 함께 출력
- 메시지 별로 보낸 시간과 메시지 키, 메시지 값, 토픽, 저장된 파티션, 저장된 오프셋 번호 출력
- 메시지가 모두 전송된 이후 통계값 출력
- 평균 처리량 확인
확인
bin/kafka-verifiable-consumer.sh --bootstrap-server {인스턴스 IP}:9092 \\ --topic verify-test \\ --group-id test-group // 컨슈머 그룹 지정 {"timestamp":1673512877251,"name":"startup_complete"} {"timestamp":1673512877442,"name":"partitions_assigned","partitions":[{"topic":"verify-test","partition":0}]} {"timestamp":1673512877517,"name":"records_consumed","count":10,"partitions":[{"topic":"verify-test","partition":0,"count":10,"minOffset":0,"maxOffset":9}]} {"timestamp":1673512877530,"name":"offsets_committed","offsets":[{"topic":"verify-test","partition":0,"offset":10}],"success":true}- 컨슈머는 토픽에서 데이터를 가져오기 위해 파티션에 할당한다.
- 여기서는 0번 파티션이 할당
- 컨슈머는 한 번에 다수의 메시지를 가져와 처리한다.
- 한 번에 10개의 메시지를 정상적으로 받음
kafka-delete-records.sh
💡 적재된 토픽의 데이터를 지우는 방법
가장 오래된 데이터부터 특정 시점의 오프셋까지 삭제할 수 있다.
ex) test 토픽의 0번 파티션에 0~100 데이터가 들어가 있을 경우
- 0번 파티션에 저장된 데이터 중 0부터 30 오프셋 데이터까지 지우고 싶을 때
vi delete-topic.json {"partitions" : [{"topic" : "test", "partition": 0, "offset": 50}], "version":1 } bin/kafka-delete-records.sh --bootstrap-server 3.34.137.108:9092 \\ --offset-json-file delete-topic.json // 삭제 토픽, 파티션, 오프셋에 대한 정보를 담은 json 파일을 읽어서 데이터 삭제 진행- 삭제가 완료되면 각 파티션에서 삭제된 오프셋 정보를 출력한다.
❗토픽의 특정 레코드하나만 삭제되는 것이 아니다.
- 파티션에 존재하는 가장 오래된 오프셋부터 지정한 오프셋까지 삭제된다.
❗카프카에서는 토픽의 파티션에 저장된 특정 데이터만 삭제할 수 없다.
참고 자료
http://www.yes24.com/Product/Goods/99122569
'📕 book > 아파치 카프카' 카테고리의 다른 글
4장. 카프카 상세 개념 - 토픽과 파티션 (0) 2023.01.17 Kafka 스트림즈 구현 (0) 2022.09.18 3장 - 카프카 스트림즈 (0) 2022.09.18 3장 - 카프카 기본 개념 (0) 2022.09.18 1장 - 들어가며 (0) 2022.09.18