-
ElasticSearch🔍 elastic search 2022. 9. 20. 18:14
Apache Lucene(아파치 루씬) 기반의 Java 오픈 소스 분산형 RESTful 검색 및 분석 엔진
Elasticsearch를 통해 루씬 라이브러리를 단독으로 사용할 수 있으며,
방대한 양의 데이터를 신속하게( 거의 실시간) 저장, 검색, 분석을 수행할 수 있다.
특히 정형 데이터, 비정형 데이터, 지리 데이터등 모든 타입의 데이터 처리 가능ES는 JSON 문서(Document)로 데이터를 저장하기 때문
HTTP 프로토콜로 접근이 가능한 REST API를 통해 데이터 조작을 지원ElasticSearch는 단독 검색을 위해 사용하거나,
ELK(ElasticSearch & Logstash & Kibana) 스택을 기반으로 사용
- 주로 ELK는 로드밸런싱되어 있는 WAS의 흩어져 있는 로그를 한 곳으로 모으고, 원하는 데이터를 빠르게 검색한 뒤 시각화하여 모니터링 하기 위해 사용
구조

클러스터
클러스터란 Elasticsearch에서 가장 큰 시스템 단위를 의미, 최소 하나 이상의 노드로 이루어진 노드의 집합
서로 다른 클러스터는 데이터 접근, 교환을 할 수 없는 독립적인 시스템
여러 대의 서버가 하나의 클러스터를 구성할 수 있고, 한 서버에 여러 개의 클러스터가 존재할 수 있다.
노드
노드는 클러스터에 포함된 단일 서버
- 데이터를 저장하고 클러스터의 색인화 및 검색 기능에 참여
- 역할에 따라 Master-eligible, Data, Ingest, Tribe 노드로 구분 가능
Shard
데이터를 분산해서 저장하는 방법을 의미
Scale-Out을 위해 Index(RDB의 Database와 상응) 를 여러 shard로 쪼갬
- 기본적으로 1개가 존재, 검색성능 향상을 위해 클러스터 shard 개수를 조정 할 수 있다.
shard
인덱스의 도큐먼트를 분산 저장하는 저장소
- 샤드의 개수에 따라 도큐먼트를 분산해서 저장

노드 추가시 샤드(초록색)가 각 노드로 분배되어 저장
- 처음에 생성된 샤드를 Primary Shard라고 한다.
Replica

Primary Shard의 복제본 - Replica Shard
- 서로 다른 노드에 저장
하나의 노드가 죽어도 데이터가 유실되지 않게 되어 가용성과 무결성을 보장
Primary 샤드가 유실될 경우 남아 있던 복제본이 Primary shard가 되고 다른 노드에 새로 복제본을 생성.
세그먼트
세그먼트란 elasticsearch에서 document의 빠른 검색을 위해 설계된 자료구조.
각 샤드는 다수의 세그먼트로 구성되어 있다.
elasticsearch에서 Document를 저장하면, 이 것을 메모리에 모아두고 새로운 세그먼트를 디스크에 기록하여 리프레쉬(refresh)한다.
- 이로 인해 새로운 검색 가능한 세그먼트가 만들어지게 된다.
특징
Scale out
sharding(샤딩)을 통해 규모를 수평적으로 늘릴 수 있다.
고가용성
Replica를 통해 데이터의 안정성을 보장, 단일 장애점을 극복
Schema Free
JSON 문서를 통해 데이터를 검색하므로, 스키마 개념이 없다.
Restful
CRUD 작업은 RESTful API를 통해 수행
각각 HTTP GET / POST / PUT / DELETE 메서드에 대응
역색인
특정 단어를 찾을 떄 단어가 포함된 특정 문서의 위치를 알아내어 빠르게 결과를 찾아낼 수 있다.
색인 / 역 색인
Elasticsearch는 특정 문장을 입력받으면, 파싱을 통해 문장을 단어 단위로 분리하여 저장. 또한, 대문자를 소문자로 치환하거나 유사어 체크등의 추가 작업을 통해 텍스트 저장.Elasticsearch는 역 색인 이라고 하는 자료 구조를 사용
- 전문 검색에 있어 빠른 성능을 보장
책의 전반부에 나와있는 목차를 index로, 후반부에 키워드마다 내용을 정리할 수 있도록 돕는 목차가 Reverted Index라고 생각하면 편하다.
색인 (index)
일반적인 데이터베이스에서는 단 방향 색인을 사용
- 특정 키워드를 포함하고 있는 문서를 찾기 위해서는 모든 문서의 내용을 읽어 키워드의 포함 여부에 대한 검사를 통해 찾는다.

색인을 사용한 검색 역색인
특정 키워드(term)를 포함하고 있는 문서들에 대한 Primary Key를 맵핑하는 인덱스 테이블을 생성하며, 이 테이블을 활용하여 빠른 문서 탐색을 가능하게 한다.
- 검색 엔진에서 역색인 인덱스 테이블은 주로 BTree, Trie, Hash Table 등의 자료구조를 활용하여 구현된다.
각 Document에 등장하는 모든 고유한 단어들을 리스트 업하고, 해당 단어들이 등장하는 Document들을 식별한다.
- 색인은 최적화된 Document 컬렉션이며,
- 각 Document는 데이터를 포함하고 있는 Key-Value 쌍으로 이루어진 Field의 컬렉션
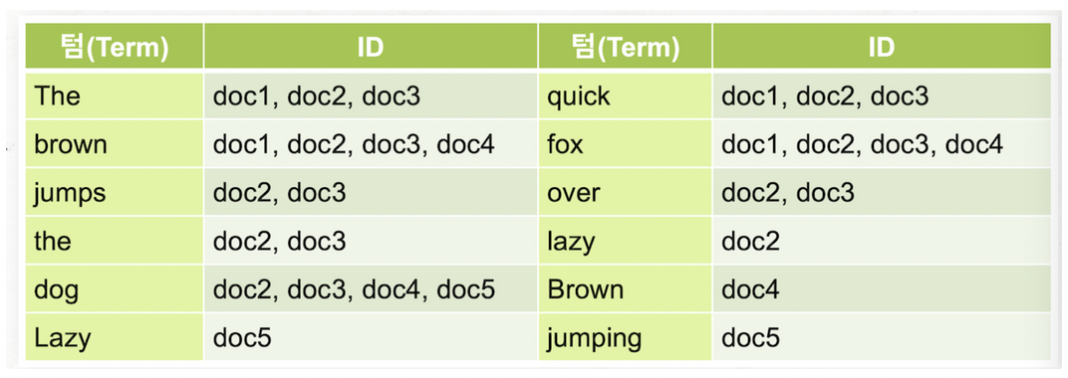
역 색인을 사용한 검색 데이터가 저장되는 과정에서 역색인을 만들기 때문에, 검색엔진은 데이터를 입력할 때 저장이 아닌 색인을 한다고 표현한다.
ElasticSearch / RDBMS
엘라스틱 서치 관계형 데이터베이스 인덱스 (index) 데이터베이스 (database) 샤드 (shard) 파티션 (partition) 타입 (type) 테이블 (table) 문서 (document) 행 (row) 필드 (field) 열 (column) 매핑 (mapping) 스키마 (schema) QueryDSL SQL Elasticsearch는 데이터를 행렬 데이터로 저장하는 것이 아닌,
JSON 문서(Document) 로 직렬화된 복잡한 자료구조를 저장하는 방식을 채택하고 있다.
따라서, 기존 RDB에서 사용하던 용어를 그대로 사용하지 않는다.
RDB는 데이터 수정과 삭제의 편의성과 속도면에서 강점이 있다.
- 하지만, 다양한 조건의 데이터를 검색하고 집계하는 데에는 구조적인 한계가 존재
- 특정 단어 검색시 ROW 개수 만큼 확인을 반복
반면, 단어 기반으로 데이터를 저장하는 ES는 특정 단어가 어디에 저장되어 있는지 이미 알고 있어 모든 Document를 검색할 필요가 없다.
- 수정과 삭제는 내부적으로 굉장히 많은 리소스가 소요 → RDBMS를 대체하긴 어렵다.
DB만 있으면 되는데, 왜 굳이 검색엔진이 필요할까?
RDB에서 조건에 맞는 데이터를 SQL를 이용하여 일치하는 데이터를 검색하면 훌륭하게 데이터 검색이 가능하다. 그럼에도 왜 검색엔진이 필요할까???- 관계형 데이터베이스는 단순 텍스트 매칭에 대한 검색만을 제공한다.
- 한글 검색의 경우 많이 빈약하다.
- 텍스트를 여러 단어로 변형하거나 텍스트의 특징을 이용한 동의어나 유의어를 활용한 검색이 가능
- 엘라스틱 서치에서는 관계형 데이터베이스에서 불가능한 비정형 데이터의 색인과 검색이 가능
- 빅데이터처리에서 매우 중요
- 엘라스틱서치에서는 형태소 분석을 통한 자연어 처리가 가능
- 다양한 형태소 분석 플러그인 제공
- 역색인 지원으로 매우 빠른 검색 가능.
RESTful API를 사용하는 엘라스틱 서치
관계형 DB와 엘라스틱서치를 비교했을 때, 큰 차이점중 하나는 데이터의 CRUD를 하는 방식이다.관계형 DB인 경우, CRUD를 하기 위해 DB가 있는 서버에 연결을 맺어 SQL을 날리는 방식.
- ex) JDBC에서 RDB가 있는 IP, Port를 연결하여 쿼리를 날리는 방식
엘라스틱 서치 CRUD
데이터를 CRUD하기 위해서 RESTful API 방식을 사용
GET, POST, PUT, DELETE 등의 메소드가 RESTful API의 형식대로 그대로 적용
- HEAD 메소드는 특정 문서의 정보 유무를 확인하는데 이용될 수 있다.
POST- 데이터 삽입인 경우 관계형 데이터베이스와 다른 특성이 있다.
스키마가 미리 정의되어 있지 않더라도 자동으로 필드를 생성하고 저장 한다.
ElasticSearch 장점
1. 전문 검색(Full-text Search)
- 내용 전체를 색인하여 특정 단어가 포함된 문서를 검색 가능
2. Schemaless
- 기존 관계형 데이터베이스는 스키마라는 구조에 따라 데이터를 적합한 형태로 변경하여 저장, 관리
- ES는 비정형의 다양한 형태의 문서도 자동으로 색인, 검색 가능
3. RESTful API
- HTTP 통신 기반으로 요청을 받아 JSON 형식으로 응답
- 다양한 플랫폼에서 응용 가능
4. Multi-tenancy
- ES의 index는 RDB의 database와 같은 개념에도 서로 다른 index에서도 검색할 필드명만 같으면 여러개의 index를 한번에 조회 가능
5. 역색인
- 역색인 지원
6. 확장성과 가용성
- 분산 시스템 구성으로 병렬적인 처리 가능
- 데이터가 샤드 단위로 나뉘어 제공 index 생성 시마다 샤드의 수 조정 가능
ElasticSearch 단점
- 실시간 (Real Time) 처리는 불가능
- 데이터 색인 특징 때문에 색인된 데이터는 1초 뒤에나 검색이 가능
- 색인된 데이터가 내부적으로 커밋과 플러시와 같은 과정을 거치지 때문.
- NRT(Near Real Time)
- 트랜잭션, 롤백 등의 기능을 제공하지 않는다.
- 분산 시스템 구성의 특징 때문에 시스템 적으로 비용 소모가 큰 롤백, 트랜잭션을 지원하지 않는다.
- 데이터 관리 유의
- spring에서 제공되는 spring-data-elasticsearch에서도 마찬가지
- 그래프 데이터베이스를 제외한 NoSQL 특징과도 유사
- 진정한 의미의 업데이트(Update)를 지원하지 않는다. (데이터의 수정을 지원하지 않는다)
- 업데이트 명령이 있지만, 실제로는 데이터를 삭제(soft delete)했다가 다시 만드는 과정으로 업데이트
- update이 수정이 아닌, 삭제 + 삽입으로 수정이 이루어진다.
- 따라서 수정시 단순 업데이트에 비해 상대적으로 많은 비용 발생
- 불변성이라는 이점을 제공하기도 한다.
- 업데이트 명령이 있지만, 실제로는 데이터를 삭제(soft delete)했다가 다시 만드는 과정으로 업데이트
❓ Elasticsearch 는 왜 검색이 빠를까
기존 RDBMS와 데이터를 저장하는 방식이 다르다.
각 value(text)들이 포함된 Document들을 나열한다. → 역색인
전통적인 RDBMS에서는 like 검색을 사용하기 때문에 데이터가 늘어 날 수록 검색해야할 대상이 늘어나 시간이 오래 걸림.
- row안의 내용을 모두 읽어야 하기 때문에 기본적으로 속도가 느리다.
역색인을 사용하면 데이터가 늘어나도 찾아가야할 행 이 늘어가는 것이 아니라 역색인이 가리키는 id 배열 값이 추가되는 것으로 빠른 속도로 검색이 가능.
참고자료
검색 기능에 Elasticsearch 적용하기 - Milestone | Joanne Blog
'🔍 elastic search' 카테고리의 다른 글
ES - Aggregations (0) 2022.09.22 ES - 텍스트 분석 (0) 2022.09.22 ES - 데이터 검색 (1) 2022.09.21 ES - 기본 API (1) 2022.09.21 Docker로 ES 설치하기 (1) 2022.09.21