-
3장 - 애그리거트📕 book/도메인 주도 개발 시작하기 2022. 11. 2. 16:05
⭐ 애그리거트
도메인 객체 모델이 복잡해지면 개별 구성요소 위주로 모델을 이해하게 되고 전반적인 구조나 큰 수준에서 도메인 간의 관계를 파악하기 어려워진다.
- 도메인 요소 간의 관계를 파악하기 어렵다는 것은 코드를 변경하고 확장하는 것이 어려워진다는 것을 의미
- 상위 수준에서 모델이 어떻게 엮여 있는지 알아야 전체 모델을 망가뜨리지 않으면서 추가 요구사항을 모델에 반영할 수 있는데, 세부적인 모델만 이해할 경우에는 코드 변경을 최대한 회피하는 쪽으로 요구사항을 협의하게 된다.
따라서, 복잡한 도메인을 이해하고 관리하기 쉬운 단위로 만들려면 상위 수준에서 모델을 조망할 수 있는 방법이 필요하다.
→ 애그리거트
- 관련된 객체를 하나의 군으로 묶음.
- 수 많은 객체를 애그리거트로 묶어서 바라보면 상위 수준에서 도메인 모델 간의 관계를 파악할 수 있다.
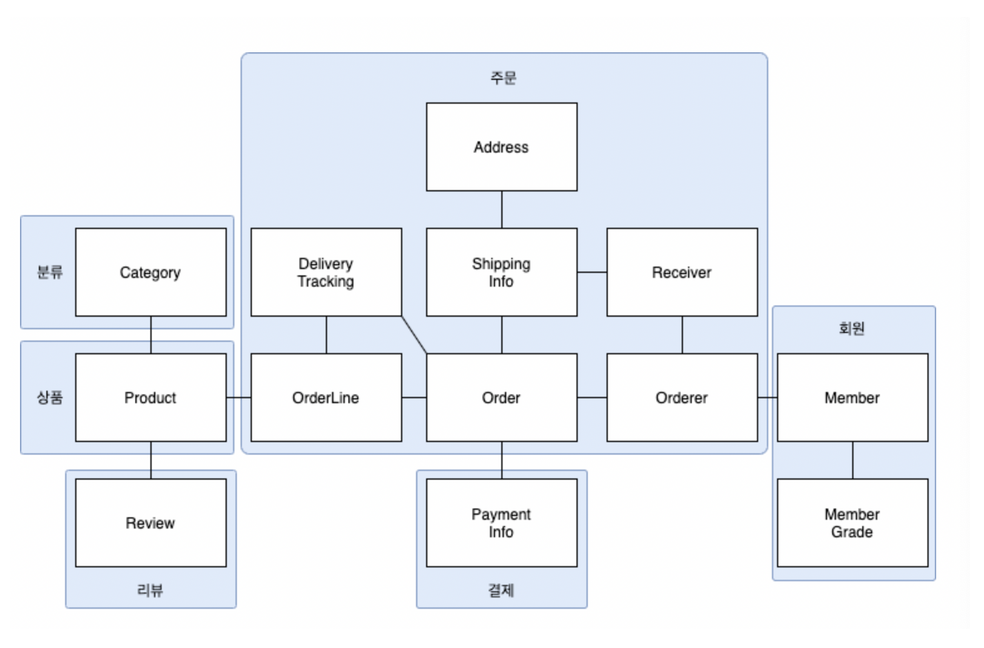
애그리거트는 모델을 이해하는 데 도움을 줄 뿐만 아니라 일관성을 관리하는 기준도 된다.
- 모델을 보다 잘 이해할 수 있고 애그리거트 단위로 일관성을 관리하기 때문에 복잡한 도메인을 단순한 구조로 만들어 준다.
애그리거트에 속한 객체는 유사하거나 동일한 라이프 사이클을 갖는다.
- 애그리거트에 속한 구성요소는 대부분 함께 생성하고 함께 제거
각 애그리거트는 경계를 갖는다
- 독립된 객체군이며 각 애그리거트는 자기 자신을 관리할 뿐 다른 애그리거트를 관리하지 않는다.
경계를 설정할 때 기본이 되는 것
- 도메인 규칙
- 요구사항
도메인 규칙에 따라 함께 생성되는 구성요소는 한 애그리거트에 속할 가능성이 높다.
- 함께 변경되는 빈도가 높은 객체는 한 애그리거트에 속할 가능성이 높다.
📌 애그리거트 루트
애그리거트는 여러 객체로 구성되기 때문에 한 객체만 상태가 정상이면 안된다.
도메인 규칙을 지키려면 애그리거트에 속한 모든 객체가 정상 상태를 가져야 한다.
애그리거트에 속한 모든 객체가 일관된 상태를 유지하려면 애그리거트 전체를 관리할 주체가 필요하다.
⇒ 이 책임을 지는 것이 애그리거트의 루트 엔티티이다.

- 주문 애그리거트의 루트 - Order
- 주문 애그리거트에 속한 모델은 Order에 직접 또는 간접적으로 속한다.
도메인 규칙과 일관성
애그리거트 루트의 핵심 역할 : 애그리거트의 일관성이 깨지지 않도록 하는 것.
이를 위해 애그리거트 루트는 애그리거트가 제공해야 할 도메인 기능을 구현한다.
애그리거트 루트가 제공하는 메서드는 도메인 규칙에 따라 애그리거트에 속한 객체의 일관성이 깨지지 않도록 구현해야 한다.
애그리거트 외부에서 애그리거트에 속한 객체를 직접 변경하면 안된다
- 이는 애그리거트 루트가 강제하는 규칙을 적용할 수 없어 모델의 일관성을 깨는 원인이 된다.
ShippingInfo si = order.getShippingInfo(); si.setAddress(newAddress);- 위 코드는 애그리거트 루트인 Order에서 ShippingInfo를 가져와 직접 정보를 변경한다.
- 이는 DB 테이블의 데이터를 직접 수정하는 것과 같다 ⇒ 논리적 데이터 일관성이 깨진다.
불필요한 중복을 피하고 애그리거트 루트를 통해서만 도메인 로직을 구현하게 만들기 위해선 도메인 모델에 대해 다음의 두 가지를 습관적으로 적용해야 한다.
- 단순히 필드를 변경하는 set 메서드를 공개(public) 범위로 만들지 않는다.
- 밸류 타입은 불변으로 구현한다.
공개(public) set 메서드를 피해야 한다.
공개 set 메서드는 도메인의 의미나 의도를 표현하지 못하고 도메인 로직을 도메인 객체가 아닌 응용 영역이나 표현 영역으로 분산시킨다.
- 유지 보수할 때도 분석하고 수정하는데 더 많은 시간이 필요
공개 set 메서드만 넣지 않아도 일관성이 깨질 가능성이 줄어든다.
- 자연스럽게 cance, changePassword 처럼 의미가 더 잘 드러나는 이름을 사용하는 빈도가 높아진다.
밸류는 불변타입으로 구현
ShippingInfo si = order.getShippingInfo(); si.setAddress(newAddress); // ShippingInfo 가 불변이면, 컴파일 에러!!- 애그리거트 외부에서 내부 상태를 함부로 바꾸지 못하므로 애그리거트의 일관성이 깨질 가능성이 줄어든다.
- 밸류 객체가 불변이면 밸류 객체의 값을 변경하는 방법은 새로운 밸류 객체를 할당하는 것 뿐이다.
public class Order { private ShippingInfo shippingInfo; public void changeShippingInfo(ShippingInfo newShippingInfo) { verifyNotYetShipped(); setShippingInfo(newShippingInfo); } // set 메서드의 접근 허용 - private private vodi setShippingInfo(ShippingInfo newShippingInfo) { // 밸류가 불변이라면 새로운 객체를 할당하여 값을 변경 // 불변으로 this.shippingInfo.setAddress(newShippingInfo.getAddress()) // 같은 코드를 사용할 수 없다. this.shippingInfo = newShippingInfo; } }밸류 타입의 내부 상태를 변경하려면 애그리거트 루트를 통해서만 가능하다!!
애그리거트 루트의 기능 구현
애그리거트 루트는 애그리거트 내부의 다른 객체를 조합해서 기능을 완성한다.
애그리거트 루트가 관리하는 도메인을 구할 수 있는 메서드를 제공하는 경우 애그리거트 외부에서 해당 도메인의 기능을 실행할 수 있다. → 일관성이 깨짐
e.g. Order.getOrderLines()
OrderLines 같이 관리하는 도메인을 불변으로 구현할 수 없다면 변경 기능을 패키지나 protected 범위로 한정해서 외부에서 실행할 수 없도록 제한.
- 보통 한 애그리거트에 속하는 모델은 한 패키지에 속하기 때문에 패키지나 protected 범위를 사용하면 애그리거트 외부에서 상태 변경 기능을 실행하는 것을 방지할 수 있다.
트랜잭션 범위
트랜잭션 범위는 작을수록 좋다.
- 여러개의 테이블을 수정 → 잠금 대상이 더 많아진다.
- 잠금 대상이 많아진다 → 동시에 처리할 수 있는 트랜잭션 개수가 줄어든다 → 전체적인 성능 저하
동일하게 한 트랜잭션에는 한 개의 애그리거트만 수정해야 한다.
- 한 트랜잭션에서 두 개이상의 애그리거트 수정시 트랜잭션 충돌이 발생할 가능성이 높다.
- 전체 처리량이 떨어진다.
한 트랜잭션으로 두 개이상의 애그리거트를 수정해야 한다면 애그리거트에서 다른 애그리거트를 직접 수정하지 말고 응용 서비스에서 두 애그리거트를 수정할 수 있도록 구현한다.
public class ChangeOrderSevice { // 두 개이상의 애그리거트를 변경해야 한다면, // 응용서비스에서 각 애그리거트의 상태를 변경 @Transactional public void changeShippingInfo(OrderId id, ShippingInfo newShippingInfo, boolean useNewShippingAddrAsMemberAddr) { Order order = orderRepository.findbyId(id); if (order == null) throw new OrderNotFoundException(); order.shipTo(newShippingInfo); if (useNewSHippingAddrAsMemberAddr) { Member member = findMember(order.getOrderer()); member.changeAddresss(newShippingInfo.getAddresss()); } }한 트랜잭션에서 두 개이상의 애그리거트를 변경하는 것을 고려하는 경우
- 팀 표준
- 팀이나 조직의 표준에 따라 사용자 유스케이스와 관련된 응용서비스의 기능을 한 트랜잭션으로 실행해야 하는 경우
- 기술 제약
- 기술적으로 이벤트 방식을 도입할 수 없는 경우 한 트랜잭션에서 다수의 애그리거트를 수정해서 일관성을 처리해야 한다.
- UI 구현의 편리
- 운영자의 편리함을 위해 주문 목록 화면에서 여러 주문의 상태를 한 번에 변경하고 싶을 때
- 이런 경우 한 트랜잭션에서 여러 주문 애그리거트의 상태를 변경
📌 리포지터리와 애그리거트
애그리거트는 개념상 완전한 한 개의 도메인 모델을 표현하므로 객체의 영속성을 처리하는
리포지터리는 애그리거트 단위로 존재해야 한다.
애그리거트는 개념적으로 하나이므로 리포지터리는 애그리거트 전체를 저장소에 영속화해야한다.
- ex) Order 애그리거트와 관련된 테이블이 3개
- Order 애그리거트 저장시 애그리거트 루트와 매핑되는 테이블뿐만 아니라
- 애그리거트에 속한 모든 구성요소에 매핑된 테이블에 데이터를 저장
애그리거트를 구하는 리포지터리 메서드는 완전한 애그리거트를 제공해야 한다.
// 리포지터리는 완전한 order를 제공해야 한다. Order order = orderRepository.findById(orderId); // order가 온전한 애그리거트가 아니면 // 기능 실행 도중 NPE 과 같은 문제 발생 order.cancle();- 완전한 애그리거트를 제공하지 않으면 필드나 값이 올바르지 않아 애그리거트의 기능을 실행하는 도중 NPE(NullPointerException) 같은 문제 발생
영속화할 저장소로 무엇을 사용하든지 간에 애그리거트의 상태가 변경되면 모든 변경을 원자적으로 저장소에 반영해야 한다.
- RDMBS로 리포지터리를 구현시 트랜잭션을 이용해 변경이 저장소에 반영되는 것을 보장
📌 ID를 이용한 애그리거트 참조
애그리거트도 다른 애그리거트를 참조할 수 있다.
- 다른 애그리거트의 루트를 참조한다는 것.
애그리거트간의 참조는 필드를 통해 쉽게 구현할 수 있다.
- JPA - @ManyToOne, @OneToMany 같은 애너테이션 사용하여 연관된 객체를 로딩
하지만 필드를 이용하면 다음 문제를 야기
- 편한 탐색 오용
- 성능에 대한 고민
- 확장 어려움
편리함을 오용
한 애그리거트 내부에서 다른 애그리거트 객체에 접근할 수 있으면 다른 애그리거트의 상태를 쉽게 변경할 수 있게 된다.
⇒ 애그리거트 간의 의존 결합도를 높여 변경을 어렵게 만든다.
성능에 대한 고민
JPA를 사용하는 경우 참조한 객체를 Lazy, Eager 로딩의 두 가지 방식으로 로딩할 수 있다.
확장
초기에는 단일 DBMS
- 이 후, 도메인별로 시스템 분리 → 서로 다른 DBMS
- 더 이상 애그리거트 루트를 참조하기 위해 JPA와 같은 단일 기술을 사용할 수 없다.
이런 세 가지 문제를 완화할 때 사용할 수 있는것 - ID를 이용해 다른 애그리거트를 참조
ID 참조를 사용하면 모든 객체가 참조로 연결되지 않고 한 애그리거트에 속한 객체들만 참조로 연결된다.
- 복잡도를 낮춘다
- 한 애그리거트에서 다른 애그리거트를 수정하는 문제를 근원적으로 방지
- 애그리거트별로 다른 구현 기술을 사용하는 것 가능
- 중요한 데이터 (주문 애그리거트) - RDBMS
- 조회 성능이 중요 (상품 애그리거트) - NoSQL 저장

ID를 이용한 참조와 조회성능
다른 애그리거트를 ID로 참조하면 참조하는 여러 애그리거트를 읽을 때 조회 속도가 문제가 될 수 있다.
ID를 이용한 애그리거트 참조는 N + 1 조회 문제 발생
⇒ 조회 전용 쿼리를 사용하여 해결!!
- ex) 데이터 조회를 위한 별도 DAO를 만들고 DAO의 조회 메서드에서 조인을 이용해 한 번의 쿼리로 필요한 데이터를 로딩
DAO
- DB의 data에 접근하기 위한 객체
- 직접 DB에 접근하여 data를 삽입, 삭제, 조회 등 조작할 수 있는 기능을 수행
애그리거트마다 서로 다른 저장소를 사용하는 경우에는 한 번의 쿼리로 관련 애그리거트를 조회할 수 없다.
이런 경우 조회 성능을 높이기 위해 캐시를 적용하거나 조회 전용 저장소를 따로 구성한다.
- 코드가 복잡해지는 단점이 있지만 시스템의 처리량을 높일 수 있다는 장점이 있다.
📌 애그리거트 간 집합 연관
애그리거트 간 1-N 과 M-N 연관
특정 카테고리에 있는 상품 목록을 보여주는 요구사항이 있다고 하자.
- 한 상품이 한 카테고리에만 속하는 경우
- 한 상품이 여러 카테고리에 속하는 경우
한 상품이 한 카테고리에만 속하는 경우
카테고리와 상품은 1-N 관계
→ 카테고리쪽에서 1:N 으로 조회하는 것이 아닌 상품 입장에서 자신이 속한 카테고리를 N:1로 연관
한 상품이 여러 카테고리에 속하는 경우
상품과 카테고리는 양방향 M-N 연관
실제 구현에서는 상품에서 카테고리로의 단방향 M-N 연관만 적용
- RDBMS를 이용한 M-N 연관을 구현하기 위해서는 조인테이블을 사용
JPA를 이용하면 다음과 같은 매핑 설정을 사용해 ID참조를 이용한 M-N 단방향 연관을 구현할 수 있다.
@Entity @Table public class Product { @EmbeddedId private ProductId id; @ElementCollection @CollectionTable(name = "product_category", joinColumns = @JoinColumn(name = "product_id")) private Set<CategoryId> categoryIds; ... }- 카테고리 ID 목록을 보관하기 위해 밸류 타입에 대한 컬렉션 매핑을 사용
상세화면과 같은 조회 기능은 조회 전용 모델을 이용해서 구현하는 것이 좋다..!
📌 애그리거트를 팩토리로 사용하기
생성할 수 있는지 없는지 확인하는 도메인 로직은 해당 도메인에서 구현
- 도메인의 응집도 높아진다
- 애그리거트를 팩토리로 사용할 때 얻는 장점!
애그리거트가 갖고 있는 데이터를 이용해서 다른 애그리거트를 생성해야 한다면 애그리거트에 팩토리 메서드를 구현하는 것을 고려해보자
- ex) Store 의 데이터를 이용해 Product 생성
- Product를 생성할 수 있는 조건을 판단할 때 Store의 상태를 이용
public class Store { public Product creatProduct(ProductId newProductId, ...) { if(isBlock()) throw new StoreBlockedException(); return new Product(newProductId, ....); } }참고 자료
http://www.yes24.com/Product/Goods/108431347
도메인 주도 개발 시작하기 - YES24
가장 쉽게 배우는 도메인 주도 설계 입문서!이 책은 도메인 주도 설계(DDD)를 처음 배우는 개발자를 위한 책이다. 실제 업무에 DDD를 적용할 수 있도록 기본적인 DDD의 핵심 개념을 익히고 구현을
www.yes24.com
'📕 book > 도메인 주도 개발 시작하기' 카테고리의 다른 글
6장 - 응용 서비스와 표현 영역 (0) 2023.01.05 5장 - 스프링 데이터 JPA를 이용한 조회 기능 (0) 2023.01.05 4장 - 리포지터리와 모델 구현 (0) 2023.01.02 2장 - 아키텍처 개요 (0) 2022.10.27 1장 - 도메인 모델 시작하기 (0) 2022.10.04